DOM(文档对象模型)定义了一种访问和操作文档的标准。它是一个平台和语言无关的接口,允许程序和脚本动态访问和更新文档的内容、结构和样式。HTML DOM用于操作HTML文档,而XML DOM用于操作XML文档。
HTML DOM示例
This is a Heading
This is another Heading
XML DOM示例
DOM的编程接口由一组标准属性和方法定义。属性通常用于描述节点的特征,而方法通常用于执行与节点相关的操作。
属性的例子
x.nodeName - x的名称x.nodeValue - x的值x.parentNode - x的父节点x.childNodes - x的子节点x.attributes - x的属性节点方法的例子
x.getElementsByTagName(name) - 获取指定标签名的所有元素x.appendChild(node) - 将一个子节点插入到xx.removeChild(node) - 从x中移除一个子节点这些属性和方法使得通过编程可以访问和操作文档的各个部分。
根据 XML DOM,XML 文档中的所有内容都是节点:
DOM 示例
看下面的 XML 文件(books.xml):
Everyday Italian
Giada De Laurentiis
2005
30.00
Harry Potter
J.K. Rowling
2005
29.99
XQuery Kick Start
James McGovern
Per Bothner
Kurt Cagle
James Linn
Vaidyanathan Nagarajan
2003
49.99
Learning XML
Erik T. Ray
2003
39.95
上述 XML 中的根节点命名为
文档中的所有其他节点都包含在
根节点
第一个
子节点分别包含一个文本节点,内容分别为 "Everyday Italian"、"Giada De Laurentiis"、"2005" 和 "30.00"。
在 DOM 处理中常见的错误是期望元素节点包含文本。然而,元素节点的文本存储在文本节点中。
在这个例子中:
"2005" 不是
XML DOM 将 XML 文档视为树结构。树结构被称为节点树。
所有节点都可以通过树访问。它们的内容可以修改或删除,并且可以创建新元素。
节点树显示了节点集和它们之间的连接。树从根节点开始,延伸到树的最低层的文本节点:
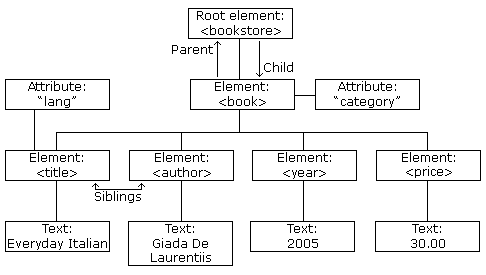
图像上方代表 XML 文件 books.xml。
节点树中的节点之间存在层次关系。
术语父节点、子节点和兄弟姐妹用于描述这些关系。父节点有子节点。在同一层级上的子节点称为兄弟姐妹。
以下图像说明了节点树的一部分以及节点之间的关系:

由于 XML 数据是以树形式结构化的,可以在不知道树的确切结构和包含的数据类型的情况下遍历它。
看下面的 XML 片段:
Everyday Italian
Giada De Laurentiis
2005
30.00
在上述 XML 中,
此外,
使用 DOM,您可以访问 XML 文档中的每个节点。
有三种方式可以访问节点:
getElementsByTagName() 方法getElementsByTagName() 方法getElementsByTagName() 返回具有指定标签名的所有元素。
语法
node.getElementsByTagName("tagname");
示例
以下示例返回 x 元素下的所有
x.getElementsByTagName("title");
注意,上面的示例仅返回 x 节点下的
xmlDoc.getElementsByTagName("title");
其中 xmlDoc 是文档本身(文档节点)。
getElementsByTagName() 方法返回一个节点列表。节点列表是节点的数组。
x = xmlDoc.getElementsByTagName("title");
x 中的
y = x[2];
注意:索引从 0 开始。
length 属性定义了节点列表的长度(节点数)。
您可以通过使用 length 属性循环遍历节点列表:
var x = xmlDoc.getElementsByTagName("title");
for (i = 0; i XML 文档的 documentElement 属性是根节点。
节点的 nodeName 属性是节点的名称。
节点的 nodeType 属性是节点的类型
以下代码循环遍历根节点的子节点,这些子节点也是元素节点:
txt = "";
x = xmlDoc.documentElement.childNodes;
for (i = 0; i ";
}
}
示例解释:
xmlDoc 中xmlDoc)的子节点以下代码使用节点之间的关系导航节点树:
x = xmlDoc.getElementsByTagName("book")[0];
xlen = x.childNodes.length;
y = x.firstChild;
txt = "";
for (i = 0; i ";
}
y = y.nextSibling;
}
示例解释:
xmlDoc 中book 元素的子节点book 元素的第一个子节点nodeName 属性指定节点的名称。
nodeName 是只读的。nodeName 与标签名相同。nodeName 是属性名。nodeName 始终是 #text。nodeName 始终是 #document。nodeValue 属性指定节点的值。
nodeValue 是未定义的。nodeValue 是文本本身。nodeValue 是属性值。以下代码检索第一个
var x = xmlDoc.getElementsByTagName("title")[0].childNodes[0];
var txt = x.nodeValue;
结果:txt = "Everyday Italian"
示例解释:
books.xml 加载到 xmlDoc 中。txt 变量设置为文本节点的值。以下代码更改了第一个
var x = xmlDoc.getElementsByTagName("title")[0].childNodes[0];
x.nodeValue = "Easy Cooking";
示例解释:
books.xml 加载到 xmlDoc 中。nodeType 属性指定节点的类型。
nodeType 是只读的。元素节点的 attributes 属性返回属性节点的列表。
这称为命名节点映射,与节点列表类似,只是在方法和属性上有一些差异。
属性列表会自我更新。如果删除或添加了属性,列表会自动更新。
此代码片段从 "books.xml" 中的第一个
x = xmlDoc.getElementsByTagName('book')[0].attributes;
执行上述代码后,x.length 是属性的数量,x.getNamedItem() 可用于返回一个属性节点。
此代码片段获取书籍的 "category" 属性值和属性列表的数量:
x = xmlDoc.getElementsByTagName("book")[0].attributes;
txt = x.getNamedItem("category").nodeValue + " " + x.length;
输出:
示例解释:
books.xml 已加载到 xmlDoc 中。x 变量以保存第一个 为了方便其他设备和平台的小伙伴观看往期文章:
微信公众号搜索:Let us Coding,关注后即可获取最新文章推送
看完如果觉得有帮助,欢迎点赞、收藏、关注
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部